 Transformer Explainability
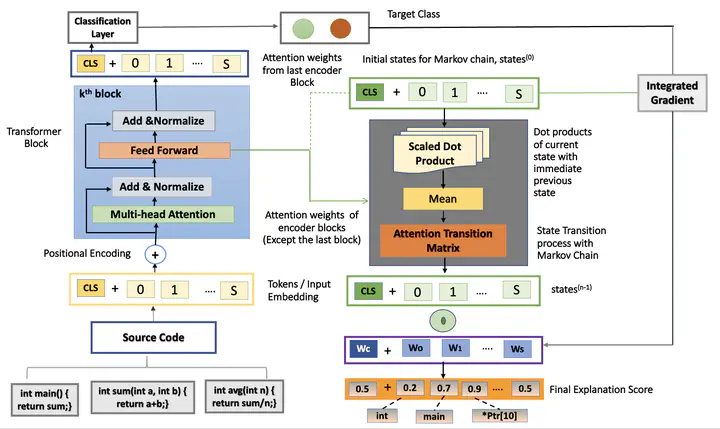
Transformer ExplainabilityTransformer-based models show significant performance in Natural Languages Processing (NLP) and Computer Vision (CV). CodeBERT is a recent transformer-based model that achieved state-of-the-art source code vulnerability detection performance. Although CodeBERT can predict whether an input code is vulnerable or not, there is no way to explain which features of the input source code are responsible for that prediction. Different explainability tools are proposed to compute the relevance of input tokens for the model decisions. However, none of them considers the information flow across layers of the transformers and provides the class discriminative explanation. In this project, we propose an explanation approach that leverages the information flow across layers of the codeBERT model using the idea of the Markov chain and the integrated gradient. Our model outperforms the baseline model by at least 2.57% top-10 accuracy.
Md Mahbubur Rahman
PhD Student at Computer Science
My research interests include AI for Code, Software Engineering and Deep Learning.